2017年中国大数据产业 数据处理与存储服务的深化与突破
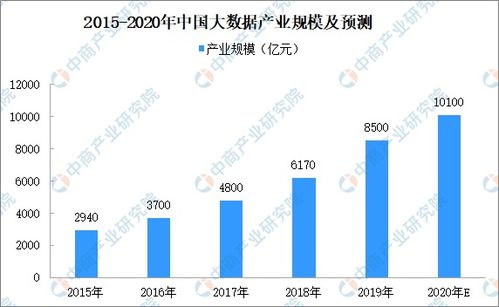
2017年,中国大数据产业在经历了前几年的概念普及与初步发展后,迈入了深化应用和夯实基础的关键阶段。其中,作为产业基石的数据处理与存储服务领域,呈现出技术加速演进、市场格局重构、服务模式创新和政策环境优化的鲜明特征,为整个产业的健康发展提供了强劲动力。
一、技术演进:云化、智能化与实时化成为核心驱动力
在数据处理层面,批处理与流处理融合成为主流。以Apache Spark、Flink为代表的新一代计算框架,因其在内存计算、流处理性能上的优势,得到广泛应用,推动数据处理从传统的离线批量模式向实时、准实时分析迈进。以机器学习、深度学习为代表的人工智能技术与数据处理流程深度结合,自动化数据清洗、特征工程和模型训练,显著提升了数据处理的智能化水平。
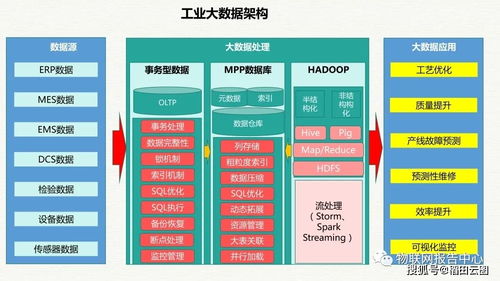
在数据存储层面,混合云与多云架构成为企业首选。公有云凭借弹性伸缩、成本灵活的优势,在非核心、高弹性业务场景中占据主导;而私有云和本地部署则在数据安全、合规性要求高的核心业务中坚守阵地。对象存储因其海量、非结构化数据存储的优势得到大规模应用。为满足不同业务需求,多模数据库(Multi-Model Database)兴起,能够在同一数据库内核中支持文档、键值、图、关系等多种数据模型,简化了技术栈。
二、市场格局:服务商竞合加剧,生态化趋势明显
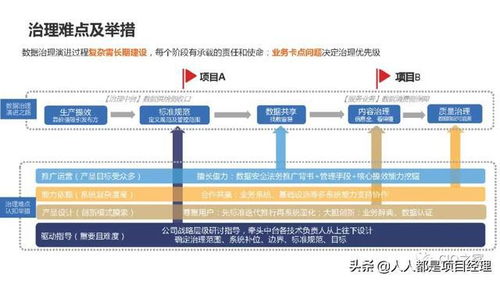
市场竞争方面,形成了以阿里云、腾讯云、华为云等互联网与ICT巨头为首的公有云服务商阵营,以及一批在特定行业或技术领域有深厚积累的专业数据处理与存储解决方案提供商。巨头依托其庞大的生态体系,提供从IaaS到PaaS、乃至SaaS的一站式服务,构建护城河。专业厂商则深耕垂直行业(如金融、政务、工业),提供定制化、高可靠性的解决方案,竞争焦点从单纯的产品性能转向整体服务能力、行业理解与生态整合。
三、服务模式创新:从资源供给到价值赋能
数据处理与存储的服务内涵发生深刻变化。单纯提供存储空间和计算资源的“资源型”服务利润空间被压缩,服务商纷纷向“平台型”和“赋能型”升级。具体表现为:
- 数据湖(Data Lake)服务普及:帮助企业集中存储原始格式的海量数据,为后续的探索性分析和机器学习提供统一的“数据水源”,打破了传统数据仓库的结构化限制。
- Serverless(无服务器)计算兴起:用户无需关心底层服务器配置和管理,只需按实际使用的计算资源付费,极大降低了大数据处理的技术门槛和运维成本,尤其受到中小企业和创业公司的欢迎。
- 数据管理服务(Data Management as a Service, DMaaS)初露头角:提供涵盖数据集成、质量治理、安全脱敏、生命周期管理的一站式托管服务,帮助企业应对日益复杂的数据管理挑战。
四、政策与环境:合规要求提升,驱动服务标准化
2017年,《中华人民共和国网络安全法》正式施行,对数据的安全存储、跨境传输和个人信息保护提出了明确且严格的法律要求。这直接驱动数据处理与存储服务商将安全与合规能力建设提升到战略高度。数据本地化存储、加密传输与存储、细粒度的访问控制、完备的审计日志成为服务产品的“标准配置”。政策压力客观上加速了行业服务标准的形成和技术的规范化发展。
五、挑战与展望
尽管发展迅速,2017年的数据处理与存储服务领域仍面临挑战:数据孤岛现象依然存在,跨系统、跨组织的数据流动与处理效率有待提升;面对爆炸式增长的数据量,存储与计算的成本控制压力持续;兼具大数据技术和行业知识的复合型人才严重短缺。
随着5G、物联网技术的部署,边缘计算将与云计算协同,推动数据处理向边缘延伸,形成“云-边-端”一体化的数据处理架构。在数据安全与隐私保护法规日趋完善的背景下,以隐私计算(如联邦学习、安全多方计算)为代表的技术,将在保障数据安全的前提下,促进数据价值的流通与释放,为数据处理与存储服务开辟新的蓝海。
总而言之,2017年是中国大数据产业中数据处理与存储服务领域承前启后的一年。它在技术融合、市场演进、模式创新和合规驱动下,变得更加成熟、务实和以价值为导向。这一年的发展为后续产业全面迈向以数据智能为核心的新阶段,奠定了坚实的技术基础与服务框架。
如若转载,请注明出处:http://www.cxyftechnology.com/product/18.html
更新时间:2026-06-18 23:38:05