运行分析中的数据处理与存储服务 构建洞察力的数字基石
在当今数据驱动的时代,无论是复杂的工业设备、庞大的IT系统,还是日常的应用程序,其“运行分析”已成为优化性能、预测故障和提升效率的核心手段。而支撑这一分析过程的幕后英雄,正是高效、可靠的数据处理与存储服务。它们共同构成了从原始数据到决策洞察的价值转化管道。
一、数据处理服务:从混沌到有序的炼金术
运行分析的第一步是处理海量、高速、可能杂乱无章的原始运行数据。数据处理服务在此环节扮演着“炼金术士”的角色。
- 实时流处理:对于监控指标、日志流等需要即时响应的数据,采用如Apache Kafka、Apache Flink、Spark Streaming等技术。它们能对数据进行实时清洗、过滤、聚合和初步计算,确保异常能被瞬间捕捉,为实时告警和仪表盘提供动力。
- 批量数据处理:对于历史数据、周期性报表和深度挖掘任务,则依赖如Apache Hadoop、Spark等批量处理框架。它们擅长处理TB/PB级别的数据,执行复杂的转换、关联和统计运算,为趋势分析和模型训练准备高质量的数据集。
- 数据清洗与标准化:这是提升数据质量的关键步骤。服务需要处理数据缺失、异常值、格式不一致等问题,并将来自不同源头(如传感器、日志文件、数据库)的数据转换为统一的模型和格式,为后续分析扫清障碍。
二、数据存储服务:洞察力的持久化仓库
处理后的数据需要被妥善存储,以供即时查询、历史回溯和模型迭代。根据访问模式和性能要求,存储服务呈现出分层、多模的特点。
- 热数据存储(实时/高频访问):
- 时序数据库(TSDB):如InfluxDB、Prometheus、TDengine,专为时间序列数据(如CPU使用率、温度读数)优化,提供极高的写入与查询效率,是运行监控场景的标配。
- 内存数据库/缓存:如Redis、Memcached,存储需要毫秒级响应的关键指标或中间结果,极大提升分析应用的性能。
- 温数据存储(交互式分析):
- 关系型数据库(RDBMS):如MySQL、PostgreSQL,适用于存储结构严谨、需要复杂事务和关联查询的元数据、配置信息及聚合结果。
- 分析型数据库/数据仓库:如ClickHouse、Apache Doris、Snowflake,专为复杂OLAP查询设计,能快速对海量历史运行数据进行多维度聚合分析。
- 冷数据存储(归档与深度挖掘):
- 对象存储:如Amazon S3、阿里云OSS、MinIO,以其近乎无限的扩展性和极低的成本,成为存储原始日志、长期历史备份数据的理想选择,通常与计算引擎(如Spark)结合进行偶尔的深度分析。
三、服务融合:构建端到端的分析管道
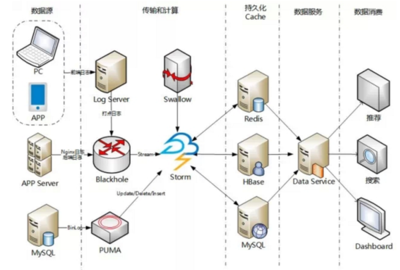
现代运行分析平台并非孤立的服务堆砌,而是通过管道化、服务化的方式紧密集成。典型架构如下:
- 数据采集层:代理(如Fluentd、Logstash)或SDK从各种源头收集数据。
- 消息队列层:如Kafka,作为数据的缓冲区和总线,解耦采集与处理。
- 核心处理层:流处理引擎进行实时处理,批量处理引擎进行周期性作业。
- 分层存储层:根据数据温度,分别存入TSDB、数据仓库和对象存储。
- 服务与API层:对外提供统一的查询API、数据订阅和告警服务。
四、核心挑战与未来趋势
- 挑战:面对数据量指数增长,如何保证处理的低延迟与高吞吐?如何实现存储的成本与性能最优平衡?如何确保数据在整个管道中的安全、合规与一致性?
- 趋势:
- 云原生与Serverless化:采用Kubernetes编排数据处理任务,利用云上托管的、按需伸缩的存储与计算服务,降低运维复杂度。
- 湖仓一体与数据编织:打破数据湖(灵活)与数据仓(严谨)的界限,在统一架构上同时支持实时查询、批处理和AI/ML,并通过智能的数据编织(Data Fabric)技术自动化数据管理。
- 智能化数据处理:将AI融入管道,实现异常检测的自动化、数据质量的智能治理和存储策略的动态优化。
###
运行分析中的数据处理与存储服务,是连接物理世界运行状态与数字世界决策智慧的桥梁。它们从纷繁的数据洪流中提炼信号,并将其沉淀为可追溯、可挖掘的知识资产。构建一个弹性、高效、智能的数据处理与存储体系,已成为任何组织在数字化转型中获取持续竞争力的技术基石。这一领域将继续向自动化、一体化与智能化的方向演进,为更复杂、更精准的运行分析提供无穷动力。
如若转载,请注明出处:http://www.cxyftechnology.com/product/26.html
更新时间:2026-06-18 11:03:23